메소드는 일반적인 객체의 멤버 함수를 의미합니다.
지역 함수는 함수 안에 정의된 함수를 의미하며 이 지역 함수는 지역 함수를 감싸고 있는 블록 내에서만 접근 가능합니다.
스칼라는 기본적으로 복잡한 함수를 다수의 작은 함수로 나눠야 하는 설계 원칙을 가지고 있습니다. 그래서 도우미 함수가 다수 존재합니다.
도우미 함수는 클래스 외부에서 사용하지 않고 클래스 내부에서만 사용되는 함수입니다. 도우미 함수는 외부에 노출될 필요가 없기 때문에 private 키워드를 사용하거나 지역 함수를 사용하게 됩니다.
지역 함수는 지역 함수를 감싸고 있는 블록 내에서만 접근 가능하기 때문입니다.
코드를 보면 processLine 함수가 processFile 안에 정의되어 있습니다. 따라서 processLine은 지역함수가 되고 processFile 블록 내에서만 호출 가능해 외부의 접근을 차단합니다.
그리고 변수의 스코프에 따라 processFile의 인자 filename과 width가 processLine에서 사용가능 하기 때문에 processLine에서 별도로 인자 값을 받을 필요가 없습니다. 그래서 오른쪽 코드와 같이 바꿀 수 있습니다.

스칼라는 1급 계층 함수를 제공합니다. 1급 계층 함수는 함수를 정의하고 호출할 뿐만 아니라 이름 없이 리터럴로 표기해 값처럼 주고 받을 수 있습니다.
값처럼 주고 받을 수 있기 때문에 함수 반환 값, 인자로 전달 가능하고 특정 변수에 담을 수도 있습니다.
여기서 리터럴은 예와 같이 함수를 표현한 소스코드 자체를 의미하고 이런 함수 리터럴은 FunctionN 클래스로 컴파일됩니다. 만약 인자가 하나라면 Function1, 인자가 두 개라면 Function2 클래스로 컴파일 됩니다.
이런 컴파일된 클래스를 실행 시점에 인스턴스화해 객체로 만들면 이를 함수 값이라고 부릅니다.
그래서 아래 예처럼 함수 값은 인스턴스화된 객체이기 때문에 변수에 저장할 수도 있고 함수 값은 함수이기도 하기에 함수를 호출하는 방식으로 함수를 호출할 수 있습니다.
또한 var 변수이기에 다른 함수 값으로 변경 가능하고 함수 리터럴 내부가 여러 줄을 표현된다면 중괄호로 감싸면 됩니다.

함수 리터럴을 간단하게 만드는 방법을 살펴보겠습니다.
위 예는 1,2,3,4,5,6 원소를 가지는 리스트를 정의하고 foreach를 통해 numbers의 요소를 순회하면서 print 하는 예입니다.
foreach 내부에 함수 리터럴이 사용됐습니다.
이 함수 리터럴의 인자 타입을 컴파일러가 추론할 수 있다면 인자 타입을 제거할 수 있습니다. 예에서는 numbers의 원소가 이미 Int인 것을 numbers를 정의할 때 알 수 있습니다.
그래서 컴파일러는 foreach 내부 x 원소가 Int인 것을 알기 때문에 타입을 명시해주지 않아도 타입을 추론 가능합니다. 그래서 인자 타입 제거가 가능합니다.
또한 타입 추론이 이뤄진 인자를 둘러싼 괄호를 제거해서 더 간단한게 나타낼 수 있습니다.
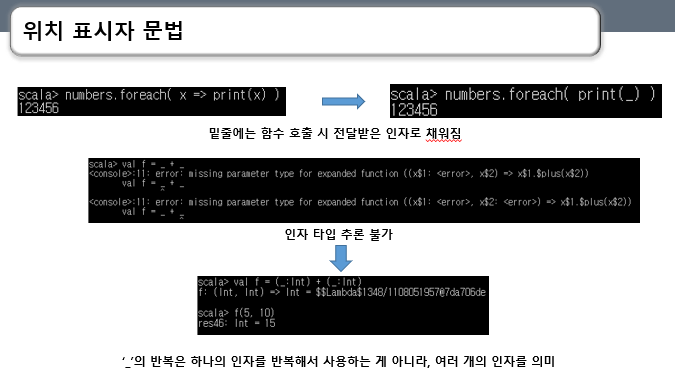
위치 표시자 문법은 기존 함수 리터럴을 더 간결하게 만들기 위해 사용합니다.
코드와 같이 “x=>” 화살표를 생략하고 “x=>”를 생략하게 되면 foreach 함수 리터럴 내부에서 사용되는 각 원소를 식별할 수 있는 식별자가 없기 때문에 “_”를 사용해 함수 호출 시 전달받은 인자가 채워지도록 할 수 있습니다.
이 밑줄을 위치 표시자라고 하고 위치 표시자는 컴파일러가 인자의 타입 정보를 찾지 못할 경우 인자의 타입을 명시해야 합니다.
“_+_” 함수 값을 정의하면 다음과 같이 파라미터의 타입을 찾지 못한다고 에러가 납니다. 컴파일러에서 +메서드를 호출해야하는 데 무슨 객체의 +메소드를 호출해야할 지 모르기 때문입니다.
그래서 인자 타입 추론이 불가능하면 타입을 명시해줘야 합니다.
“_+_”를 보면 첫 번째 _에는 첫 번째 인자가 들어가고 두 번째 _에는 두 번째 인자가 들어가는 걸로 볼 때 “_”을 반복해서 사용하는 것은 하나의 인자를 반복해서 사용하는 게 아니라 여러 개의 인자라는 걸 의미합니다.
즉, 위치 표시자는 함수 내부에서 하나의 파라미터에 대해 여러 번이 아닌 한번만 사용 가능합니다.
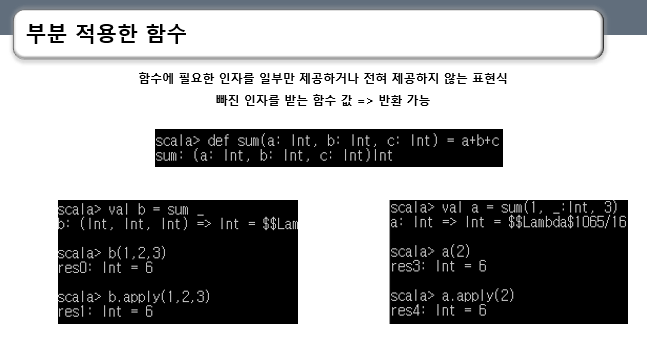
부분 적용한 함수는 함수에 필요한 인자를 일부만 제공하거나 전혀 제공하지 않는 표현식을 의미합니다.
예를 보면 인자 세 개를 더하는 sum 메소드를 정의합니다. 그리고 왼쪽 코드와 같이 sum _ 을 해주면 b 변수에 a,b,c 3개의 인자를 요구하는 함수 값 객체가 만들어집니다.
b가 함수 값 객체이기 때문에 함수처럼 호출이 가능하고 3개의 인자를 요구하기 때문에 3개의 인자를 넣어 호출할 수 있습니다.
스칼라 컴파일러 내부적으로는 sum _ 이 b에 할당될 때 3개의 인자를 요구하는 클래스 인스턴스를 만들고 b(1,2,3)과 같이 호출을 할 때 b.apply로 바꾸게 됩니다.
인자 일부만 적용하고 싶다면 오른쪽과 같이 제공하지 않는 인자에 위치표시자를 명시해 주면 됩니다.

이 부분 적용한 함수는 함수 값이기 때문에 반환이 가능합니다.
왼쪽 코드는 f 메소드의 지역 함수 g를 함수 값 객체로 반환하는 것인데 g만 적어주면 이 것은 메소드 이름을 가리키지 함수 값 객체를 가리키지 않기 때문에 이 때 부분 적용한 함수를 사용할 수 있습니다.
또한 함수가 필요한 시점이라면 “_”를 사용하지 않아도 됩니다.

“ (x:Int) => x+more” 함수 리터럴이 있을 때 x는 바운드 변수 more은 자유 변수라고 합니다. X는 주어진 함수 내에서만 의미가 있고 함수의 호출이 끝나면 x 변수는 사라집니다.
more는 함수 내부에서 사용되지만 외부에 정의되어 있어 함수 자체에만 의미를 부여하지 않습니다.
“ (x:Int) => x+1” 처럼 자유 변수가 없는 함수 리터럴은 닫힌 코드 조각이라 하고 자유 변수가 있는 함수 리터럴은 열린 함수 조각이라고 합니다.
이 열린 함수 조각에서는 함수 외부에서 정의된 자유 변수 값을 알아야 하는 데 이를 위해서 실행 시점에 자유 변수에 대한 바인딩을 캡처합니다. 즉, 자유 변수의 실제 값이나 위치를 얻어서 자유 변수에 값을 지정해서 자유변수를 없앱니다.
즉, 열린 함수 조각을 자유 변수를 없애 닫힌 코드 조각처럼 닫는 다고 해서 자유 변수가 있는 열린 함수 조각을 클로저라고 합니다.

클로저는 자유변수 바인딩을 가지고 있기 때문에 자유 변수의 변화를 감지합니다.
클로저는 생성될 때 자유 변수를 바인딩합니다. 코드에서 more 변수는 makeIncreaser의 인자이기 때문에 호출 후 사라져서 실제 inc1() 과 같이 호출할 때 more 값이 없을 것 같지만
캡쳐된 자유 변수는 메소드의 스택이 아닌 힙에 배치되서 makeIncreaser 메소드보다 더 오래 살아남을 수 있습니다.

반복 파라미터는 함수의 마지막 파라미터를 반복 가능하다고 지정할 수 있어서 마지막 파라미터를 가변 인자처럼 사용 가능합니다.
반복 파라미터를 사용하려면 “*”을 마지막 인자의 타입 다음에 추가하면 됩니다.
예제의 “String*”는 Array[String]을 의미합니다.
그렇다고 String*의 인자에 Array[String] 변수를 전달하면 에러가 납니다. 배열을 반복 인자로 전달하기 위해서는 “: _*”를 추가해야 합니다.


재귀가 while 보다 성능이 떨어지는 이유는 재귀 함수가 호출될 때마다 함수에 대한 스택이 생성되어야 하고 재귀 함수 리턴 후 돌아가야할 함수의 스택 주소를 계속 저장해야 하기 때문입니다.

왼쪽 코드는 재귀 함수 호출 후 +1을 하기 때문에 꼬리 재귀가 아닙니다.
오류 내용을 보면 boom을 여러 번 호출합니다.
오른쪽 코드는 꼬리 재귀 함수인데 bang을 한 번만 호출하고 재귀 호출 하지 않는 걸 볼 수 있습니다.
꼬리 재귀는 동일한 함수를 직접 재귀 호출하는 경우에만 최적화를 수행합니다.
왼쪽과 같이 2개의 함수가 서로 번갈아가면서 호출하는 경우, 오른쪽과 같이 함수값을 호출하는 경우 꼬리 재귀 최적화가 이루어지지 않습니다.
'스칼라' 카테고리의 다른 글
| 스칼라 10장 상속과 구성(Programming in Scala, 3rd) (0) | 2019.06.01 |
|---|---|
| 스칼라 9장 흐름 제어 추상화(Programming in Scala, 3rd) (0) | 2019.06.01 |
| 스칼라 7장 내장 제어 구문(Programming in Scala, 3rd) (0) | 2019.05.31 |
| 스칼라 6장 함수형 객체(Programming in Scala, 3rd) (0) | 2019.05.21 |
| 스칼라 5장 기본 타입과 연산(Programming in Scala, 3rd) (0) | 2019.05.21 |