: 카산드라는 select 쿼리를 할 때 where 조건에 partition key와 cluster key 밖에 사용하지 못 한다. 그 외 column을 조건으로 쿼리가 불가능하기 때문에 테이블을 추가로 만들어서 partition/cluster key를 다르게 해 데이터를 중복 저장한다. 이를 denormalization 이라고 하고 어떻게 쿼리를 할 지에 따라 데이터를 모델링하는 것을 query-driven 방식이라고 한다.
: Secondary Index는 partition/cluster key를 조건으로 해서 쿼리할 수 밖에 없는 한계를 극복하고자 등장했다. 즉, column value based query를 가능하게 한다.
: "Cassandra 3.X High Availabiliy"에 나온 예를 통해 자세히 알아보자. 아래는 Name을 row key로 하는 authors 테이블이다.
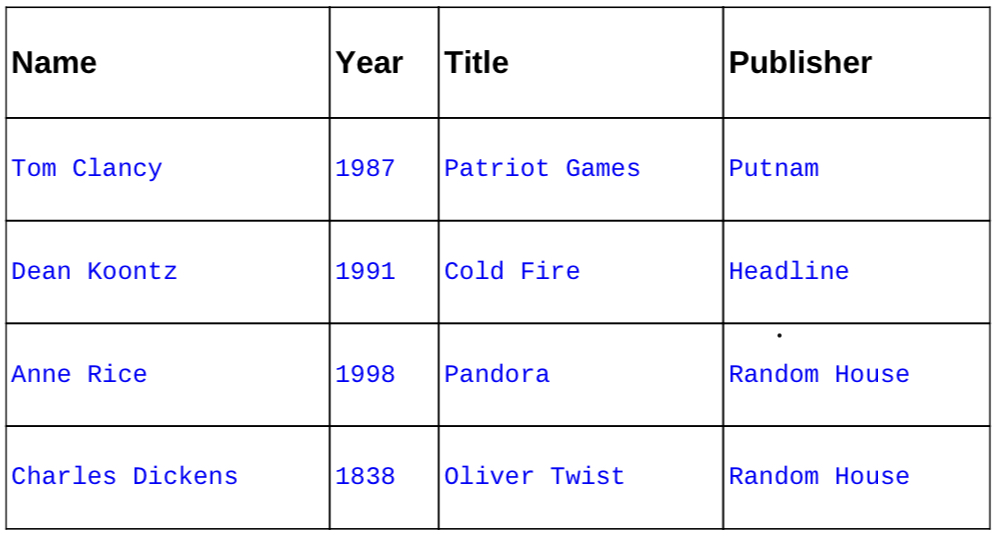
Name 칼럼이 partition key 이기 때문에 아래와 같은 쿼리는 불가능하다. 그러나 secondary index로 Publisher을 설정하면 가능하다.
select * from authors where Publisher="Putnam";
이는 기존 카산드라 쿼리 제약성을 극복한 것처럼 보이지만 내부 구조를 보면 쓰기 꺼림직하다.
카산드라는 실제 데이터를 가진 테이블과 별개로 Secondary Index 정보를 가진 테이블을 아래와 같이 유지한다. Secondary Index로 설정한 값은 row key가 되고 기존 데이터의 row key는 value가 된다.
Row Key: Putnam
=> (name=Tom Clancy, value=)
Row Key: Headline
=> (name=Dean Koontz, value=)
Row Key: Random House
=> (name=Anne Rice, value=)
=> (name=Charles Dickens, value=)
그래서 Secondary Index를 통해 쿼리를 할 때, 두 단계를 거친다.
1. Secondary Index 테이블을 통해 찾고자 하는 값에 대한 실제 데이터의 row key를 얻는다.
2. 첫 번째 단계에서 얻은 row key를 가지고 실제 데이터에 접근한다.
위 방식은 where 절에 in을 포함하는 쿼리와 거의 비슷하다. in 쿼리는 여러 partition을 접근하기 때문에 비효율적이다. secondary index도 마찬가지다. secondary index는 이 뿐만 아니라 다른 단점도 있다. secondary index 테이블은 실제 데이터 테이블과 같은 노드에 위치한다. (아래 그림 참조) 그래서 클라이언트가 secondary index와 관련된 request를 요청하면 이 request는 모든 노드에게 퍼진다. 왜냐하면 카산드라는 특정 partition key에 해당하는 데이터가 어느 노드에 있는 지 확률적으로 알 수 있지만 일반 칼럼 value는 어느 노드에 있는 지 모르기 때문이다. 또한 모든 secondary index가 한 곳에 모여 있는 것도 아니다. 이와 같은 절차 때문에 특정 partition에만 보내는 쿼리보다 성능상 부하가 많아지고 모든 노드가 request 에 정상적으로 응답하는 보장이 없기 때문에 가용성도 떨어진다.

따라서 카산드라에서 secondary index는 사용하지 않는 게 가장 좋다. 어쩔 수 없이 사용해야 한다면 성능/가용성 측면에서 critical하지 않아야 한다.
'cassandra' 카테고리의 다른 글
| 카산드라는 Null 값을 가지는 칼럼이 없다. (0) | 2020.01.16 |
|---|---|
| Cassandra(카산드라) Denormalization과 logged batch (0) | 2020.01.15 |
| 카산드라 데이터 모델링은 query-driven(쿼리 기반) 방식을 사용해야 한다. (0) | 2020.01.13 |
| Cassandra(카산드라) Partition(파티션)/Cluster key에 대해서 (0) | 2020.01.06 |
| Cassandra/카산드라 소개 및 특징 (0) | 2019.12.16 |